Batch Tool
Author: Ju4t
Batch-Tool 介绍
Batch Tool工具是专为 PolarDB-X数据库提供数据导入导出服务的工具。
其结合分布式数据库特点实现一站式且高效地从文件导入、导出到文件以及跨库的离线数据迁移(MySQL / PolarDB-X 1.0 / PolarDB-X 2.0)等功能,
在此基础上,还支持基于文本文件批量更新、删除等功能 (实验特性)。
快速上手
常见场景与问题排查可参考文档
参数介绍
命令行用法:java -jar batch-tool.jar --help
usage: BatchTool [-batchsize <size>] [-col <col1;col2;col3>] [-comp <NONE | GZIP>] [-con <consumer count>]
[-config <filepath>] [-cs <charset>] [-D <database>] [-DDL <NONE | ONLY | WITH>] [-dir <directory
path>] [-encrypt <NONE | AES | SM4>] [-error <max error count>] [-f <filepath1;filepath2>] [-F <file
count>] [-fcon <parallelism>] [-format <NONE | TXT | CSV | XLS | XLSX>] [-func <true | false>] [-h
<host>] [-H <filepath>] [-header <true | false>] [-help] [-i <true | false>] [-in <true | false>]
[-initSqls <sqls>] [-key <string-type key>] [-L <line count>] [-lastSep <true | false>] [-lb <true |
false>] [-local <true | false>] [-mask <Json format config>] [-maxConn <max connection>] [-maxWait
<wait time(ms)>] [-minConn <min connection>] [-noEsc <true | false>] [-o <operation>] [-O <asc | desc>]
[-OC <col1;col2;col3>] [-p <password>] [-P <port>] [-para <true | false>] [-param
<key1=val1&key2=val2>] [-perf <true | false>] [-pre <prefix>] [-pro <producer count>] [-quote <AUTO |
FORCE | NONE>] [-readsize <size(MB)>] [-rfonly <true | false>] [-ringsize <size (power of 2)>] [-s
<separator char or string>] [-sharding <true | false>] [-t <tableName>] [-tps <tps limit>] [-u
<username>] [-v] [-w <where condition>]
-batchsize,--batchSize <size> Batch size of insert.
-col,--columns <col1;col2;col3> Target columns for export.
-comp,--compress <NONE | GZIP> Export or import compressed file (default NONE).
-con,--consumer <consumer count> Configure number of consumer threads.
-config,--configFile <filepath> Use yaml config file.
-cs,--charset <charset> The charset of files.
-D,--database <database> Database name.
-DDL,--DDL <NONE | ONLY | WITH> Export or import with DDL sql mode (default NONE).
-dir,--directory <directory path> Directory path including files to import.
-encrypt,--encrypt <NONE | AES | SM4> Export or import with encrypted file (default NONE).
-error,--maxError <max error count> Max error count threshold, program exits when the
limit is exceeded.
-f,--file <filepath1;filepath2> Source file(s).
-F,--filenum <file count> Fixed number of exported files.
-fcon,--forceConsumer <parallelism> Configure if allow force consumer parallelism.
-format,--fileFormat <NONE | TXT | CSV | XLS | XLSX> File format (default NONE).
-func,--sqlFunc <true | false> Use sql function to update (default false).
-h,--host <host> Host of database.
-H,--historyFile <filepath> History file name.
-header,--header <true | false> Whether the header line is column names (default
false).
-help,--help Help message.
-i,--ignore <true | false> Flag of insert ignore and resume breakpoint (default
false).
-in,--whereIn <true | false> Using where cols in (values).
-initSqls,--initSqls <sqls> Connection init sqls (druid).
-key,--secretKey <string-type key> Secret key used during encryption.
-L,--line <line count> Max line limit of one single export file.
-lastSep,--withLastSep <true | false> Whether line ends with separator (default false).
-lb,--loadbalance <true | false> Use jdbc load balance, filling the arg in $host like
'host1:port1,host2:port2' (default false).
-local,--localMerge <true | false> Use local merge sort (default false).
-mask,--mask <Json format config> Masking sensitive columns while exporting data.
-maxConn,--maxConnection <max connection> Max connection count (druid).
-maxWait,--connMaxWait <wait time(ms)> Max wait time when getting a connection.
-minConn,--minConnection <min connection> Min connection count (druid).
-noEsc,--noEscape <true | false> Do not escape value for sql (default false).
-o,--operation <operation> Batch operation type: export / import / delete /
update.
-O,--orderby <asc | desc> Order by type: asc / desc.
-OC,--orderCol <col1;col2;col3> Ordered column names.
-p,--password <password> Password of user.
-P,--port <port> Port number of database.
-para,--paraMerge <true | false> Use parallel merge when doing order by export
(default false).
-param,--connParam <key1=val1&key2=val2> Jdbc connection params.
-perf,--perfMode <true | false> Use performance mode at the sacrifice of compatibility
(default false).
-pre,--prefix <prefix> Export file name prefix.
-pro,--producer <producer count> Configure number of producer threads (export /
import).
-quote,--quoteMode <AUTO | FORCE | NONE> The mode of how field values are enclosed by
double-quotes when exporting table (default AUTO).
-readsize,--readSize <size(MB)> Read block size.
-rfonly,--readFileOnly <true | false> Only read and process file, no sql execution (default
false).
-ringsize,--ringSize <size (power of 2)> Ring buffer size.
-s,--sep <separator char or string> Separator between fields (delimiter).
-sharding,--sharding <true | false> Whether enable sharding mode (default value depends on
operation).
-t,--table <tableName> Target table.
-tps,--tpsLimit <tps limit> Configure of tps limit (default -1: no limit).
-u,--user <username> User for login.
-v,--version Show batch-tool version.
-w,--where <where condition> Where condition: col1>99 AND col2<100 ...
命令主要分别为两个类别:
- 数据库连接配置,包括:
- 基础连接信息:主机、端口、用户、密码等
- 连接池配置:最大、最小连接数等
- JDBC连接串参数
- 批处理配置,包括:
- 批处理功能参数
- 待操作表名、文件名列表
- 分隔符、是否以分隔符结尾、字符集、引号转义等文本文件读取/写入相关参数
- 文件数量、文件行数等导出配置
- insert ingore、断点续传等导入配置
- where、order by等sql条件
- 压缩算法、加密算法、脱敏算法
- 文件格式:csv、excel、txt等
- 批处理性能参数
- 生产者、消费者并行度设置
- ringBuffer缓冲区、批数量、读取文件块等大小设置
- pre partition、local merge等
- tps限流相关
场景示例
在无特殊说明的情况下,下文中导入导出默认指定的文件分隔符是, ,以及字符集是utf-8。
1. 假设需要导出 tpch 库下的 customer 表(分库分表模式)
1. 默认导出,文件数等于表的分片数:
shell
java -jar batch-tool.jar -P 3306 -h 127.0.0.1 -u user_test -p 123456
-D tpch -o export -t customer -s ,
2. 导出为三个文件:
shell
java -jar batch-tool.jar -P 3306 -h 127.0.0.1 -u user_test -p 123456
-D tpch -o export -t customer -s , -F 3
3. 导出为多个文件,单个文件最大行数为 100000 行:
shell
java -jar batch-tool.jar -P 3306 -h 127.0.0.1 -u user_test -p 123456
-D tpch -o export -t customer -s , -L 100000
4. 指定 where 条件,默认导出:
shell
java -jar batch-tool.jar -P 3306 -h 127.0.0.1 -u user_test -p 123456
-D tpch -o export -t customer -s , -w "c_nationkey=10"
5. 如果文本字段包含分隔符,则指定引号模式,默认导出:
shell
java -jar batch-tool.jar -P 3306 -h 127.0.0.1 -u user_test -p 123456
-D tpch -o export -t customer -s , -quote force
2. 假设需要将csv文件导入到 tpch 库下的 lineitem 表(分库分表模式),其中对应库表已创建好
1. 指定单个文件导入:
shell
java -jar batch-tool.jar -P 3306 -h 127.0.0.1 -u user_test -p 123456
-D tpch -o import -t customer -s , -f "./data/lineitem.tbl"
2. 指定文件夹路径下所有文件导入:
shell
java -jar batch-tool.jar -P 3306 -h 127.0.0.1 -u user_test -p 123456
-D tpch -o import -t customer -s , -dir "./data/lineitem/"
ToDo 特性
- [x] 对接新分区表
- [ ] 调优实践
- [x] 指定字段(包括顺序)的导入导出
- [ ] 简单的数据清洗,如:trim尾部空格、日期时间格式等
- [x] 数据脱敏功能,如:掩码、哈希、加密、取整等
- [ ] 可视化监控
- [x] 错误情况下的断点记录(精确到行/块)
- [x] 限流功能
- [x] 流式压缩导出/解压导入
- [x] 导出为加密文件/导入加密文件
- [x] 库级别导入导出
整体设计
以数据导入场景为例,对于单机数据库从文件导入数据,提升性能的方法通常包括:(1)将多条 insert 语句合并为一条;(2)使用 PreparedStatement 的批量插入;(3)采用多进程/多线程进行导入。而对于分布式数据库而言,如果能结合 sharding 的特性,对插入数据在客户端预先在缓冲区根据 sharding key 进行划分、再将划分好的批数据发送至数据库,则不仅可以节省CN节点的计算开销,还可以降低 CN 节点对多个 DN 节点分布式调用的开销。
整体导入的流程如下:
- 获取目标表的拓扑结构,包括划分键等元信息
- 按行读取数据文件(目前支持 rfc4180 标准的csv格式,且分隔符可为任意字符串)
- 根据(1)获取的信息计算对每行数据的分片,并放入对应的缓冲 bucket;
- 当缓冲 bucket 满时,将该批数据拼入 insert 语句发送至数据库。
在按行读取文件的步骤中,通常认为顺序读取能带来最佳的性能,因为文件系统对于顺序读的行为可以进行流水线预读。
然而在导入中,读取文件的速率是远大于划分数据、发送到数据库并等待完成这个过程的,因此,为了充分利用文件I/O、网络I/O与CPU资源,项目实现采取了生产者-消费者模型,基于Disruptor框架进行开发。
其中,生产者线程按固定大小的块(为单次I/O的整数倍大小)读取文件,并根据读取到字节流中的换行符切分出一行行数据(如果有字符串型的字段类型,需要判断换行符是否在引号中)发送至生产者-消费者的缓冲区中,为了防止同一行数据被划分到两个不同的块中,此处每次按块读取需要多读一个固定大小的padding(取4KB),保证能读取到当前块最后一行的换行符,如下图所示。
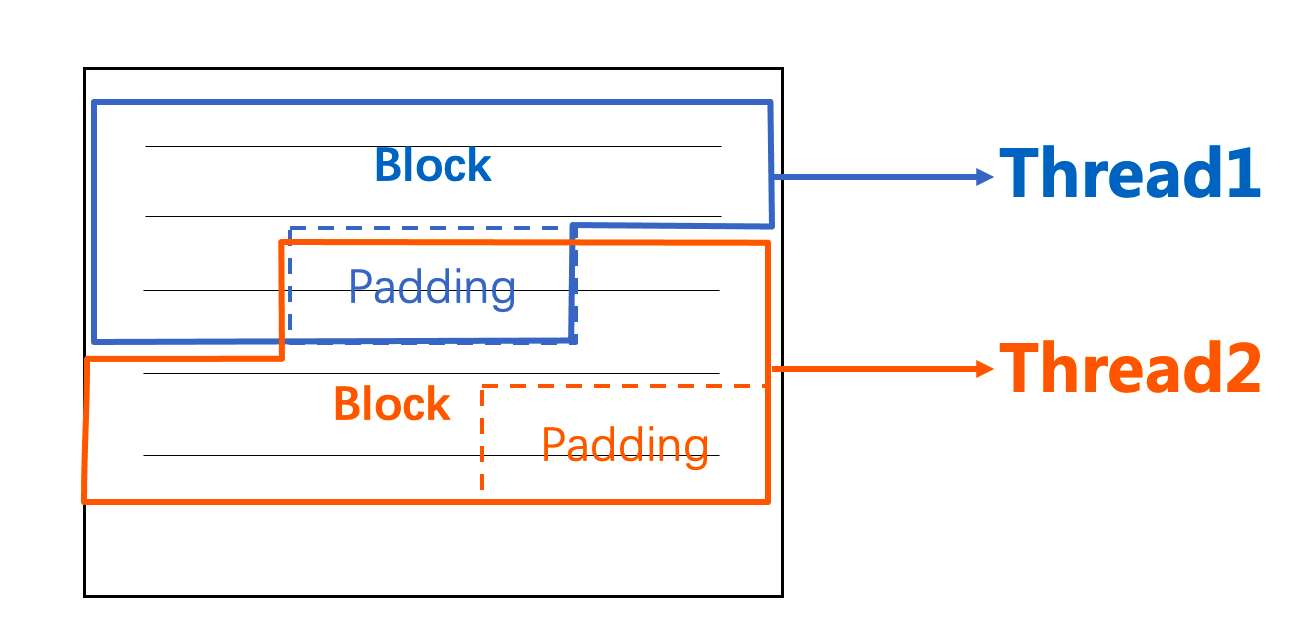
此处文件读取虽然是多线程进行的,但内核I/O调度器在实际处理 I/O请求的过程中,可能会根据特定的调度算法合并邻近的 I/O请求,以减少磁盘的寻道时间,并且如果此处是多文件的多线程读取,则I/O的调度能带来更大的提升,所以整体来说多线程的分块读取文件能契合生产者-消费者模型,平衡I/O与CPU的资源利用,带来性能上的提升。
消费者线程则负责处理已划分成行的一批数据,负责放到对应的缓冲 bucket 中,最后拼接成sql语句发送至数据库(未来将对接 batch prepare 特性,做到更高性能的数据导入)。
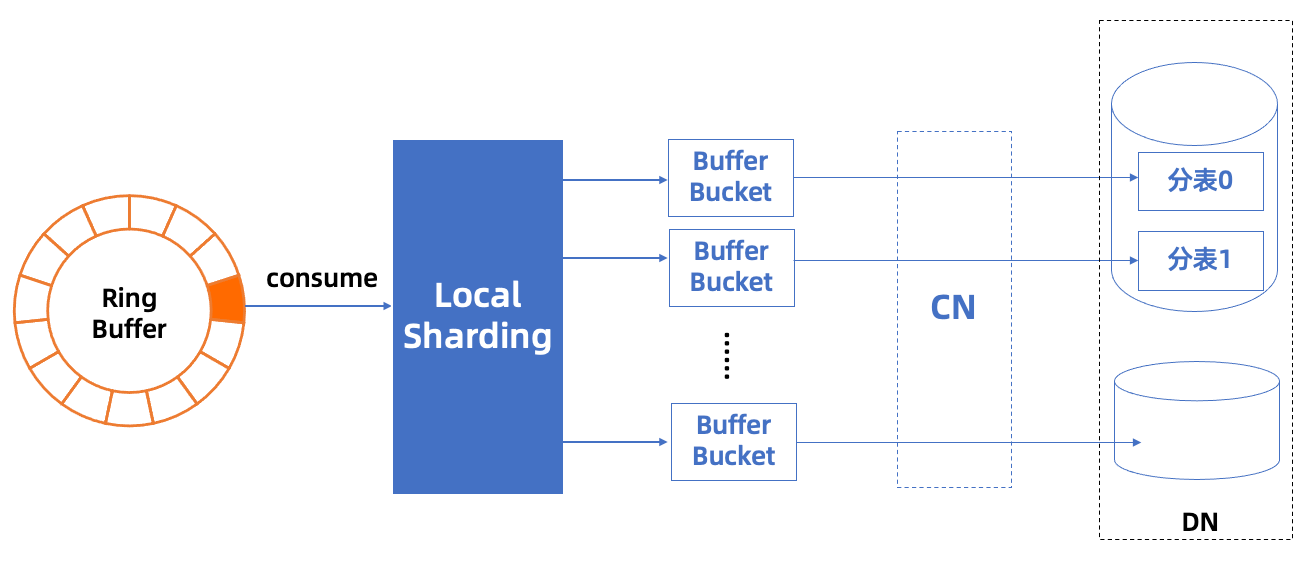
实践中,在性能方面,可以根据实际运行环境的 I/O速率、CPU负载以及网络带宽等指标来调节生产者、消费者线程的比例与并发量,同时也可根据内存大小来设置 RingBuffer 缓冲区的长度;在功能方面,可以根据选项开关,指定文件的字符集、分隔符、是否开启预分片等模式。
https://github.com/ApsaraDB/galaxysql-tools/